

【AI】ProRL/VGGT/Claude Code/第4回:最新動向調査会
2025.8.18
6月開催の第4回 AI動向調査会について共有いたします!
目次
AI最新動向調査会とは
- 参加者が気になる情報を1つずつ持ち寄る
- それぞれの技術について共有して議論する
今回の参加者は3名で、3つのトピックを共有・ディスカッションしました。
トピックは以下の3つです。
- ProRL
- VGGT
- Claude Code
1と2は論文の共有、3はAIサービスの共有です。
それでは共有された情報を紹介していきます!
各トピックの最後にはデータサイエンスチームの所感も記載されているので、ぜひご覧になってください。
1. ProRL
論文リンク
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
1-0 背景
- 近年OpenAI o3やDeepSeek R1などの“Reasoning”(推論)系モデルが登場し、推論過程における長いChain-of-Thoughtと検証・バックトラック探索によって、数学・コード生成などの複雑課題で性能を飛躍的に向上させている。
- 一方で、大規模言語モデル(LLM)に 強化学習を適用すると性能は向上するが、「強化学習が大規模言語モデルの推論能力を実際に拡張するのか、それとも既存の高報酬出力を効率的に抽出しているだけなのか」議論が続いていた。
- 先行研究では、pass@k[1] を無限大まで見ても、RLVR[2]で出た正解はもともとベースモデルが持っていたという結果もある。
優しい解説:強化学習は「隠れた正解を早く見つけるだけ」で、新しい解き方を生み出してはいない
- RLHF[3]では9B〜200B パラメータの 20 種類以上のモデルを試しても、最初に少し良くなるだけでそれ以上は伸びず、モデルが大きいほど効果が小さい。つまり 新しい推論力を付けているわけではない。
- RLHF の最適な動きは「無限にサンプルを出して一番良いものを選ぶ(Best-of-n)」と等しいと証明されており、実験でも同じ挙動を示した。結局、RLHF は“上手く抽選をしている”だけという結論になる。
- また、強化学習では学習時間を伸ばすほどエントロピー崩壊 [4] のリスクが増える。
[1]pass@k:1 問につき k 個の答えを生成し、1つでも正解なら合格と数える指標。
[2]RLVR:Reinforcement Learning with Verified Rewardsの略で、答えがはっきり決まるタスク用の強化学習
[3]RLHF:Reinforcement Learning from Human Feedbackの略で、人間のフィードバックを報酬にしてモデルを強化学習
[4]エントロピー崩壊:出力が早い段階で固定化し、多様性が失われる現象。
1-1 手法概要
- ProRL と呼ぶ長期RL手法を提案して検証。 KL距離[5]制御、参照ポリシーの定期リセット、GPROなど多様な手法群を組み合わせることで、2,000 ステップを超える訓練にも耐える安定性を確保し、ベースモデルを大幅に上回る性能を実証。
[5]KL距離・KL項:2 つの確率分布のズレ(距離)を数値で示すもの。強化学習(RL)ではこの ズレに係数 β を掛けて罰則項にする。
1‑2 手法の要点
| 仕掛け | ねらい |
|---|---|
| GRPO | 同じ問題をまとめて相対評価。価値モデルを置かずに「同じ問題をグループ化して相対評価」するため、計算が軽くブレが小さい。 |
| 改良版 DAPO | エントロピー(出力の多様さ)を維持して早期の“行き詰まり”を防ぐ。 |
| KL距離制御 (KL 正則化+参照ポリシーのリセット ) | RL学習でベースモデルから極端に離れないように調整。KL 項が強くなり過ぎたら一度リセットして学習を継続。 |
1‑3 主な結果(1.5B パラメータモデル)
| タスク | ベース比 (pass@1) |
|---|---|
| 数学 | +15.7 % |
| コード生成 | +14.4 % |
| STEM 推論 | +25.9 % |
| 命令追従 | +22.0 % |
| 論理パズル | +54.8 % |
- 2,000 ステップを超えても性能が伸び続けた。
- ベースモデル(DeepSeek-R1-Distill-Qwen-1.5B)で苦手だった問題で 100 % 正解に到達するケースもあった。
- よって、RLが新たな推論経路を開拓できることを示唆できた
1‑4 応用可能性と課題
| 視点 | 内容 |
|---|---|
| 応用可能性 | 小型モデルでも推論力を底上げできた。教育支援や自動コード修正など応用範囲が広い。 |
| 課題 | 学習に大量の GPU 時間(約 16,000 時間)が必要。ポリシーのリセットなど運用が複雑。 |
データサイエンスチーム 所感
- Appleの論文(ml-site.cdn-apple.com)では、AIは汎用推論能力は低く、汎用推論の面で考えると既存のLLMは十分な性能を持っていないのではという主張がされている。
- LLMも既存の問題やタスクのやり方に当てはめて応答しているだけなのではないか?
- 極論だと、人間もほとんどの場合で既存のパターンを当てはめて考えているだけ?
- 物理分野では、ラプラスの悪魔というこの世の全ての原子の動きを計算できれば、未来を予測することも可能という話がある。
- この世の全ての原子の動きを計算可能なのであれば、推論自体もパターンとして扱えそう。
- 推論とはそもそも何か、今後もAI分野での研究が気になる。
2. VGGT
論文リンク
VGGT: Visual Geometry Grounded Transformer
2‑0 背景
- 従来の 3D 再構成は「カメラ姿勢推定 → 点群生成 → 後処理」と多段だった。
2‑1 手法概要
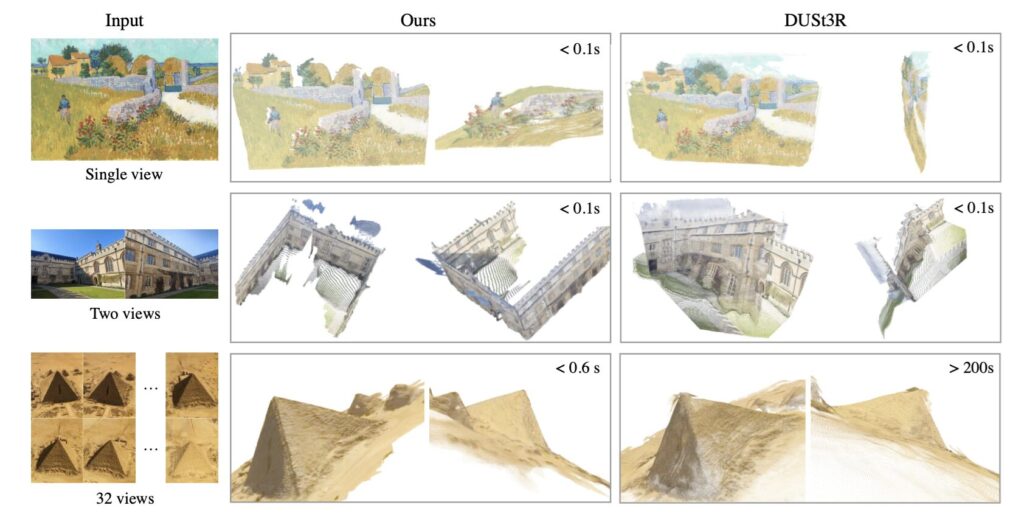
- VGGT は Transformer ベースの 1 つのネットワーク で、数枚から数百枚の画像を入力として、カメラパラメータ、深度マップ、点群、トラッキング情報など、画像の3Dタスクを一括で高速に推定できる。
- カメラ姿勢推定や点群再構成など複数のタスクでSOTAを達成
2‑2 手法の要点
- 画像をパッチに分割し、それぞれを入力トークンに。
- 画像パッチと一緒に Transformer へ渡す 「その画像を撮ったカメラの位置・向きなどを表す特別なベクトル」である、カメラトークン を追加して一緒に処理。
- フレーム内のframe-wise self-attention (local self-attention)と、フレームをまたぐ global self‑attention を交互に適用。
シンプルながら多視点情報を効率良く統合する作りをしている。
2‑3 成果
- カメラ姿勢推定や点群再構成など複数タスクで SOTA を達成。
- 後処理なしでも高精度。推定速度も向上。
2‑4 利用シーン
| 分野 | 期待できる効果 |
|---|---|
| AR/VR | ヘッドセットが空間をリアルタイム 3D 化。 |
| ロボティクス | カメラのみで自己位置推定や地図生成。 |
| デジタルツイン | 少ない写真から高品質 3D モデルを高速で生成。 |
データサイエンスチーム 所感
- 3D生成のタスクについては知見が少なかったので面白かった。
- 本手法の良い点として、高速さが挙げられていたが3D生成が高速にできることに対してのニーズはあるのか?
- 都市を丸ごと3D化するなど大規模な3D化をする際には時間がかかりすぎないのが良さそう。
3. Claude Code
3-0 Claude Codeとは?
- Claudeモデルを開発したAnthropic社がリリースしたCLI型エージェントコーディングサービス。
- 自律性が高く10分以上バグ修正を続けることが可能。
- 最近Claude Proプラン(月額20$)で利用可能になったが、5時間で10~40回の使用制限あり。Claude MAXプラン(月額100$)だと50~200回ほど。感覚だと1~2時間くらい短いコード書く場合はProプランで良いが、それ以上だとMAXが良い。
3-1 基本操作とモード
- すべて CLI。
claude <サブコマンド>がエントリーポイント。
- 詳細なコマンドは以下のURLを参照
CLIリファレンス – Anthropic
- 対話モード:履歴を残しながらコードを生成/編集。
- 非対話モード:毎回クリーンな状態で実行(履歴を参照しない)。履歴を入れないことによりトークン量削減が可能。
3-2 スラッシュコマンド
Claude Codeはスラッシュコマンドでさまざまな処理を実行できる。
/init→ プロジェクト概要を CLAUDE.md という専用ファイルにAIが自動で保存。このファイルはClaude Codeが生成を行うときにinputされるので、開発方針を書き込むと以降の生成品質が上がる。
/clear→ 会話履歴を消去。
/compact→ 履歴を自動要約してトークン節約。
- ほかにも
/help,/tokensなど、実行時に/?で一覧を確認可能。詳しくは以下のURLを参照
スラッシュコマンド – Anthropic
3-3 ファイル参照と編集支援
@ファイル名でソースを読み込みながら生成。CLAUDE.md からも@記法で再帰的に参照できる。
- 実行中に トークン数と経過時間 をリアルタイム表示。個人的にはこのトークン数のリアルタイム表示が嬉しく、どのくらいのトークンを使っているか残りの使用量の把握ができる。
Shift + Tabで提案を一括承認/解除。途中経過を見ながら、適宜一括承認として良さそうか、自分が確認するかを変更可能。
Esc×2 で会話を途中からやり直し可能。
3-4 思考深度コントロール
- Claude Codeの特徴的な機能で、思考の深さをコントロールすることができる。
- コマンドにキーワードを追加して推論の際の検討トークン量を調整。深く考えさせるほどモデルが考えるために使用できるトークン量が増える。
- 標準:
think - 中程度:
think hard / think deeply / もっと考えて - 最大:
ultrathink / 熟考深く考えて
- 標準:
- 深い設計や調査が必要な場面は
ultrathink推奨。
- プロンプト内に上記のような「特定(ultrathinkなど)の文字列が入っているか」をトリガーとして動作が変化。
3-5 IDE 連携
- Claude CodeはCLIのみの実装なので、使いやすくするためには他IDEと統合が必須。統合しないと逐一コマンドを使ってファイルを確認しなければならなかったりと不便。
- VS Code / JetBrains 拡張あり。開いているファイルを自動参照し、変更箇所をハイライト。
- IDE を使わない場合は
@で毎回ファイルを指定する必要がある。
3-6 公式おすすめ使用方法
@で関連ファイルを読み込ませる →/initで概要を固定。ultrathink指示で 設計・計画 を立てさせる ※ここまでの1.2の手順が非常に重要。公式によると、これらがないと、Claudeはすぐに解決策のコーディングに取り掛かってしまいがち。事前に深い思考を必要とする問題では、Claudeに事前に調査と計画を立ててもらうことで、「パフォーマンスが大幅に向上する」と公式に記載あり。- テストコードを生成させ、まず失敗を確認。
- テストに合格する実装を書くよう依頼し、合格まで反復。
- 変更に満足したらコミット/プルリクを作成させる。
3-7. その他 Tips
- URL を貼ると自動で内容を取得、画像もコピペ可。
- 危険操作(削除・chmod など)が含まれる生成コードは警告が出るので要確認。
- 日本語回答を保ちたいときは都度「日本語で」と指示すると安定。
- Excel など大きめデータの処理も可能だが、作業範囲を具体的に指示すると時短になる。
データサイエンスチーム 所感
- まだまだリリースして間もないサービスだが、使ってみたくなった
- Claude Codeが他社のコード生成ツールが優れている理由はなんだろう?
- エンジニアにとって使用感が良いためなのか、単純にClaude4が強いということなのか
- Claude4はGithub Copilotなどでも使用できるため単にモデルの性能だけの人気ではなさそう
- 自律的な行動について評価が高い+urtarathinkなどの制御が使いやすいのが要因としてありそう
- エンジニアにとって使用感が良いためなのか、単純にClaude4が強いということなのか
- 競合サービスのGemini CLIとの比較もしてみたい
- Gemini CLIは動画生成に使われている事例を目にした、少々使用感や得意な分野が違うのかも
以上、データサイエンスチームでした!
最後まで閲覧くださりありがとうございました。
▼これまでの最新動向調査会はこちら
第3回:最新動向調査
【AI】Logic-of-Thought(LoT)/Liquid Foundation Models (LFM)/Notebook LM音声機能追加
第2回:最新動向調査
【AI】xRAG/cRAG/TwinCAT Machine Learning Creator/xLSTM
第1回:最新動向調査
【AI】GPTsの新機能/MindGraph/RAGとデータノイズ
システム開発・保守、導入支援など、
お気軽にご相談ください





